During the summer of 2023, the Centre for Secure, Intelligent and Usable Systems in collaboration with the Design Archives and the Digital Skills in Visual and Material Culture network service at the University of Brighton hosted two research placements co-funded by Santander through the University of Brighton Undergraduate Research Scheme. Vladislav Vaculin (3rd Year, BSc Hons Mathematics) and Andrei Sobo (1st Year, BSc Hons Computer Science) from the School of Architecture, Technology and Engineering (SATE) worked closely with Dr. Karina Rodriguez Echavarria, Reader at the School of Architecture, Engineering and Mathematics, as well as Sue Breakell and Jen Grasso at the Design Archives in the School of Humanities and Social Science, to explore how machine learning methods can improve access to the University of Brighton’s Design Archives material which feeds into aggregators such as the Archives Hub, with whom the Design Archives is collaborating on a related Machine Learning project.
The research investigated the potential of Artificial Intelligence (AI)-based methods to enhance access to and dissemination of, the Design Archives’ image collections. During the project, the team gained insight into the digitisation of this material and the complexities involved in its cataloguing according to discipline-related taxonomies. Based on this joint understanding, the team explored the opportunities brought by Machine Learning, a branch of AI, which could address the challenges brought by the large scale of the data.
The challenge: Design Council’s photographic library
Jen Grasso, Digital Content & Systems Co-ordinator at the University of Brighton Design Archives, introduced the team to their photographic library developed by the Design Council. This library contains photographic material relating to the journal ‘Design’, from the first issue in 1949 until the 1980s, and photographic material relating to the Council’s various award schemes from 1957 onwards. It comprises 1) photographs of objects and environments including architecture, ceramics, clothing, domestic appliances, medical, musical instruments, textiles, tools and toys amongst other types of design; as well as 2) slides and negatives, including a large quantity of glass plates negatives which were produced by the Council in the mid-20th century. The Design Archives received the glass plates in their original boxes along with their corresponding accession books. These glass plates serve as the primary physical medium for storing the Design Council’s photographs. Moreover, photographs were classified under subject headings – chosen by the Design Council – which were adapted as the collection grew and as new images were acquired.
The process of digitization involves making high-resolution digital scanned images of the photographs and glass plate negatives, cataloguing the digital surrogates accordingly, and storing them in the Design Archive’s database. Jen shed light on the complexities involved in the cataloguing process – with over 10,000 currently digitised photographs of a total of a staggering 100,000 images in physical form and 10,000 digitised glass plates. The digitisation and cataloguing tasks already represent a significant challenge for the team. An additional hurdle arises from the fact that the glass plates’ digital images are still uncatalogued and not matched with their corresponding photographs.
Currently, the uncatalogued images are organised sequentially, as they were received from the Design Council. The sheer scale of the archives makes manual cataloguing a labour-intensive endeavour, highlighting the need for efficient solutions to streamline the cataloguing and access to valuable visual records.




Figure 1 top left) Jen Grasso and Vladislav Vaculin looking at the Design Council collection of glass plates, top right) example of boxes with glass plates, bottom left) Jen Grasso, Andrei Sobo, and Vladislav Vaculi looking at the Design Council collection of photographs, bottom right) the team discussed the process for cataloguing the images
Machine Learning and Computer Vision for Archival Processes
The project builds on previous insights that Machine Learning (ML), a particular type of Artificial Intelligence (AI) solution, can support various processes in archives, potentially automating various aspects of the digitisation and cataloguing process.
Furthermore, computer vision offers many systems and algorithms to interpret and understand visual information from digital images and videos, much like how humans perceive and interpret the visual world. Machine Learning (ML) based algorithms in computer vision have been designed to mimic human visual perception and derive meaningful insights from images. The algorithms are trained on vast amounts of labelled data, allowing them to recognize and categorize patterns, objects, and features within images, resulting in what is known as a machine learning model. Once trained, these models can quickly propose classifications for digital images, such as identifying furniture or books in an image. This automated process can support making records more accessible and searchable, as well as supporting archivists to identify valuable visual data efficiently.
Machine Learning (ML) methods usually make a distinction between supervised and unsupervised learning. The main difference is in the process which developers undertake for building these models. In supervised learning, similar images are organised into folders with named categories so the system ‘learns’ from these when the model is trained. This method usually leads to greater confidence levels in recognising images of a set number of categories. On the contrary, unsupervised learning does not require data for training. Instead, the model uses clustering and association techniques, identifying patterns in colours and shapes that allow the model to group images into meaningful groups. Unsupervised learning models can be particularly useful in large datasets where images can be grouped based on similarity, then subsequently the whole group can be catalogued.
Testing Unsupervised AI Models for Object Detection
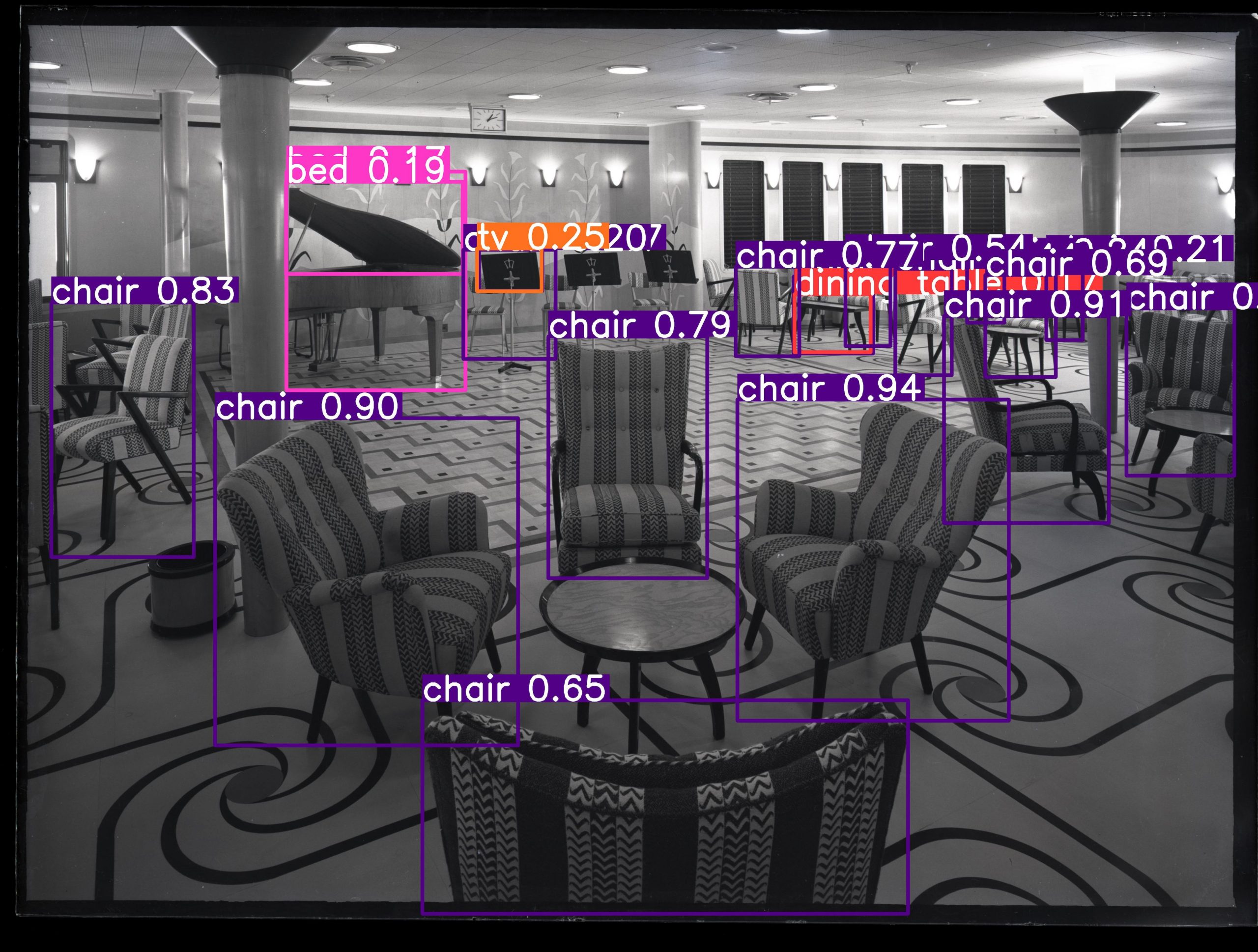
Initially, the project looked at a range of AI systems and already trained models available, including YOLO (You Only Look Once), DINO and CLIP. Figure 2 illustrates the results of applying these models by showing two images (left) which were used with all the models. YOLO was used to identify ‘generic’ objects within an image resulting in a set of ‘labels’ describing the objects found in the image along a confidence value expressed as a percentage. In Figure 2 (top-right), the model identifies various objects, defined by a bounding box, with the label ‘knife’ with a confidence value ranging from 0.84 to 0.92.


Figure 2 top-left) original image with negative number 1748-O (©CoID) Design Council Archive, University of Brighton Design Archives, top-right) 1748-O (©CoID) image with object identification with YOLO including ‘knife’ labels that describe the object and the confidence value. Bottom-left) original image 1755-O (©CoID) Design Council Archive, University of Brighton Design Archives, bottom-right) 1755-O (©CoID) image with object identification with YOLO including ‘chair’, ‘dining table’ and ‘book’ labels that describe the object and the confidence value.
A significant advantage of YOLO is that it can be used out of the box. However, a significant challenge for our purposes is that the model is able to classify the images according to the thousand different generic categories that it has been trained with, such as chairs, books, or knives in our case. Our first insight into this Machine Learning model highlighted the challenge that the classes it suggested do not correspond with the 41 categories used by the Design Council’s taxonomy. This is because the images in this, as in other Archives, are classified under a different taxonomy than what the generic ML models were trained on. The discrepancy in this classification limits its usefulness for our purposes.
Furthermore, we tested the CLIP model which allows a user to input a set of images, and use text-based search to query the images relevant to the terms in the text search. For example, Figure 3 shows the CLIP model output when searching for the word ’photography’. In this instance, the model was able to detect that there is a person and a camera in the image and gave a high possibility that this image represents a filming set.

Figure 3. Original image GB-1837-DES-DCA-30-1-TEL-TV-IL-68265-O (©CoID) Design Council Archive, University of Brighton Design Archives is selected by the CLIP model when searching for ‘photography’ in a set of images
Testing Supervised AI Models for Training
The DINO model has the capability to produce a set of masks which identify the most salient information in an image. Later in the project, the team used these masks (see Figure 4) combined with other algorithms to address the challenge of ML models classifying images under a generic set of labels. For this, we adopted a strategic approach called “retraining”, where we gathered a substantial collection of images from the archive and labelled them under the archive’s taxonomy. The team used a neural network composed of two layers which take the masks produced by DINO to offer a classification according to the taxonomy. With a model fine-tuned on the archive’s specific image collection, the process of automatically assigning accurate categories to images became more reliable and relevant, streamlining the image classification process and ensuring that the predicted categories aligned with the archive’s taxonomy.

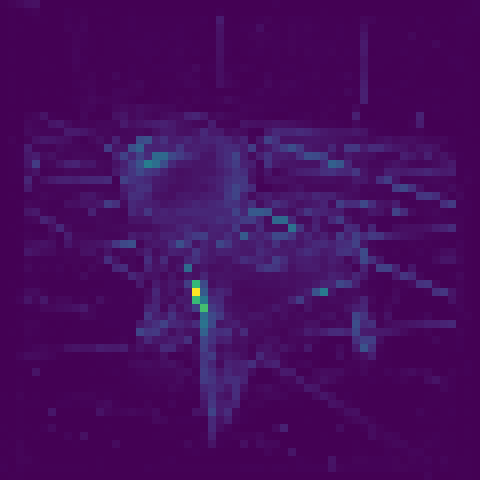



Figure 4 Examples of masks provided by DINO. Negative Number 1767-O (©CoID) Design Council Archive, University of Brighton Design Archives
In total, we re-trained two models based on different AI systems. Figure 5 shows the top three labels, including Portraits – which is the correct label – using the most accurate of the two models. To evaluate their efficiency, we conducted rigorous testing to measure their accuracy and performance. Using a separate set of images with known categories, we compared the model’s top three predictions (predicted labels) with the actual categories (true labels). The results showed significant improvement over the original implementation, with the trained model displaying a higher rate of correct predictions and increased confidence in its classifications. Overall, the model achieved 73% accuracy, while the true label was in the top three predictions on 88% of the cases. This demonstrates the value of retraining the model using the Archive’s specific image collection and using their specific taxonomy.

Figure 5. Example input impage GB-1837-DES-DCA-30-1-POR-G-4-5, Design Council Archive, University of Brighton Design Archives which displays a Portrait of James Gardner OBE RDI MSIA. The re-trained custom ML model produces three top labels: PORTRAITS 84.23%, INDUSTRIAL AND MANUFACTURING PROCESSES 1.92%, OPTICAL 1.2%.
Discussion and further work
On reflection, one of the significant challenges encountered in our research was the interpretation of images and the inherent ambiguity in their content. Images can often depict complex scenes or objects that may have multiple possible classifications, and require domain-specific knowledge so that they can be useful for further research and usage. For instance, an image containing a chair could be classified as “furniture,”, “20-century design”, “interior design,” or “artwork” amongst many other possibilities. Such ambiguity can lead to classification errors and hinder the accuracy of image categorization within subject-specific or institutional taxonomical structures.
Looking ahead, the research conducted on using AI and computer vision models for image classification in archives opens exciting possibilities for future applications. Future research include developing various methods to understand the digitised raster or pixel-based images, including recognising text as well as vectorizing design data within images, and incorporating contextual information in the ML methods.
One promising avenue is the integration of a text-based search function to complement the image classification process. By incorporating Optical Character Recognition (OCR) technology, the archive’s textual documents and records could be processed, making their content searchable. This means users could search for specific keywords or phrases within the archive’s vast collection, and relevant images associated with the text could be retrieved.
By developing methods which also analyse related images, metadata, or textual descriptions associated with the images, computer vision models could gain a better understanding of the context in which the image was captured. This approach, known as feature-level fusion has been previously applied to visual heritage collections. These advancements in deep learning techniques and multi-modal learning approaches could be result in more informed and contextually relevant classifications.
Moreover, as AI technology continues to evolve, there is potential to explore advanced image recognition techniques that can not only identify objects but also analyse high-level semantic concepts, such as emotions, sentiments, or historical context depicted in the images, adding an extra layer of understanding to the archival material and enriching our appreciation of our cultural heritage.
Further work in the development of visual analytic interactive interfaces will enable domain expertse, researchers and general users to access and gain new insights into large-scale visual collections. This research domain is still under-explored by the community. However, there is potential to leverage the richness of three-dimensional immersive environments to offer a wide range of mappings to allow for discovery of connections amongst the data, customised taxonomic classification, while offering opportunities to improve the AI-based models themselves. In this way, organisations can curate their own discipline or institution specific AI models and the data in which these models are trained on.
Finally, this project has provided us with a remarkable opportunity to delve into the potential applications of Artificial Intelligence (AI) for object detection and image classification. Leveraging neural network systems, we gained valuable insights into adapting existing computer vision models to work seamlessly with the unique category of images found in the Design Archive. Collaborating with a team of esteemed researchers and academics has been an incredible learning experience, allowing every member of the team to acquire new skills while honing existing ones. Our journey in discovering solutions to the challenges encountered during the research has been both motivating and rewarding, driving our passion to pursue this field further in our academic pursuits. As we reflect on the project’s achievements, we recognize the immense potential of AI in revolutionizing archival practices, opening new avenues for preserving and accessing historical visual data for generations to come.