
During the summer of 2024, the Computing and Mathematical Sciences Research Excellence Group in collaboration with the Design Archives, The National Archives and the Digital Skills in Visual and Material Culture network service at the University of Brighton hosted two research placements.
Isis Barrett-Lally, PhD student at the Royal Holloway University of London, and Alfie Lien-Talks, PhD student at the University of York, worked closely with Dr. Karina Rodriguez Echavarria, Reader at the School of Architecture, Engineering and Mathematics, and John Moore at The National Archives, to explore how technologies can improve the search of visual archival collections via IIIF and AI-powered semantic search. In particular, the project aimed to support GLAM’s to efficiently enable access to digitised collections for the benefit of research and cultural heritage engagement. It capitalised on the easy availability of digitised archives, including textual documents and photographic material, which inevitably results in broken data. Due to the limitations of current techniques, it can introduce transcription errors and miscategorise information. Furthermore, collection and item descriptors can vary between archives held by different institutions.
During 12 weeks, the research team identified a suitable archive on design. The interest in design content was motivated by relevant research undertaken by the team to develop AI-driven classifications of a the Design Council photographic archive. The previous project provided insights into how the study of these collections can shed insights into cultures and societies, including their aesthetics values, crafting skills and technologies.
The National Archive holds a unique resource, the UK Intellectual Property Registration Record. It contains design submissions to the UK Designs Registry, part of the Board of Trade, to be registered for copyright protection between 1839 and 1991. These include approximately 3 million designs, including textiles, glasswork, metalwork, ceramics, furniture, wallpaper in the form of drawings, paintings, photographs and product samples accompanied by a registration.
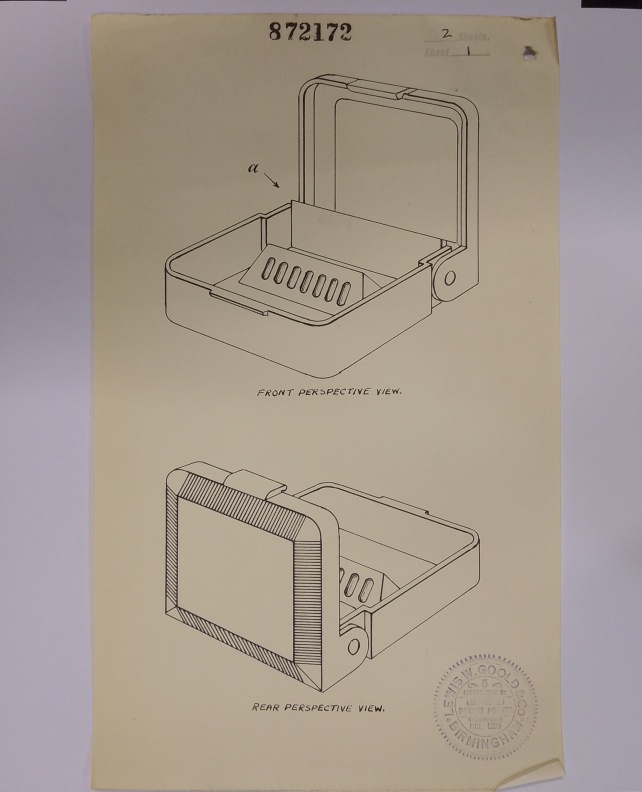

Figure 1. left) representation, and top) registration for Design No. 872172, Date of application: 20th November 1953. Description: a container for hair grips and the like. Name and address of proprietor: Kirby, Beard & Company Limited, a British Company, 498-506, Moseley Road, Birmingham, 12.
As shown in the images, the designs illustrate the outward appearance of a product or part of it, resulting from the lines, contours, colours, shape, texture, materials and/or its ornamentation. Organisations use the designs registration system to protect products, such as industrial or handicraft items, including packaging, graphic symbols and typefaces. In the archive, representations (the visual image) are in separate books than the registrations which contain important information about the design, including the date of application, a description of the design, as well as the name and address of the proprietor, as illustrated in Figure 1.
The research involved identifying some interesting data to digitise and match records, as well as to explore classifications which will help to identify specific designs which were later promoted by the Design Council. We suspected that there is a lag between a design being registered and this being ‘promoted’. A hypothesis is that the AI could help us find such trends, including, understanding how the ‘promotion’ from the Design Council affected the ‘popularity’ and ‘sales’ from such products. Firstly, we would like to understand whether this approach is feasible or not.
The proposed solution is underpinned by the interoperability and technologies offered by IIIF. The project deployed the workflow illustrated below.

Figure 2. Workflow for content discovery based on structured metadata for visual collections.
This workflow relies on the mass digitisation of archival data, which includes both registrations and representations (see Figure 1). The digitisation centred around the volume BT52 and BT53 matching registrations and representations, which is a set of non-textiles designs from early-mid 50’s. Each bound volume has 400 pages, of which only 250 contain successfully registered designs. When a certificate was not issued, potential outcomes which are written in the document include “application abandoned”, or “application withdrawn”. The digitisation took place at The National Archives during 5 days. Digitisation was set up using a phone stand over a grid to ensure uniformity, which allow to scan the documents individually. Furthermore, ArUco markers were used to allow OCR-based algorithm to extract the main information (see Figure 3). This setup allowed to take out the pages from the binder and lay them flat on the desk to photograph them. Using this method, around 50 pages can be done per hour.


Figure 3. ArUco markers are used in the digitisation to identify the relevant information.
Once all images have been acquired for the volume, each raster image is processed to extract the key information of the image. For the registrations, which contain the metadata, an OCR librart and a geometry-based strategy is used to identify the key metadata. The script generates an OCR output which contains bounding boxes in the image, and its respective text. The coordinates of the bounding boxes are then compared to a 2D-coordinate grid-template as shown in the image below to identify the nature of the metadata (e.g. date of application, date of certificate being issued, etc).

Figure 4. Geometry-based approach is used to identify key areas in the document,
The metadata is output in a CSV file, along with the paradata relevant to the digitsation, and filenames, Furthermore, the representation raster (in JPG or PNG) are processed via OCR mostly to identify the registration number. A similar approach is used, and the CSV file is produced containing similar paradata and filename. Thereafter, both lists were verified by a human, to correct mistakes of the OCR. For instance, the number “9”, “8” and “3” are many times confused with each other causing many mistakes in the registration numbers. Once the files are verified, the two lists are matched against each other to bring together the metadata both of the registration and the representations.
In total, ~700 records bringing together images of designs with their registration (metadata) were produced. Metadata included the date of application, the applicant as well as a description of the design. Additional notes such as copyright expired or extended were included.
To allow for discoverability, the IIIF framework was explored. AI-powered semantic search allowed us to search and retrieve images beyond exact matches using Large Language Model (LLM) capabilities. Currently, it is possible to search IIIF manifests using keyword search via the IIIF Content Search API. Keyword search finds exact matches within IIIF manifests for known queries, using specified search terms. The project further augments this built-in search capability, while addressing problems with the visual collections, including missing metadata.
The approach involved generate IIIF manifests with the generated images and metadata. A IIIF manifest was generated using annotations to include the metadata. The tool annotass was used to turn the IIIF manifest containing the annotations into a content search service. The annocoda web app is then deployed to provide image search capabilities by matching the term with the image annotations.

Figure 5. Annocoda interface to search for images of “chair”.
AI therefore provided us with a solution for making image records searchable, structuring metadata that did not match text and visual items. This capability has the potential to support comparative design and other visual cultural research and discovery at scale. In the future, we intend to show how semantic search can connect archives by implementing search term agnostic queries. In this way, IIIF can allow us to support search across archives with different database conventions so that users can explore these records in one place.
Acknowledgements
We would like to extend our gratitude to all of whom made this project possible, including the PhD students, Isis Barrett-Lally, PhD student at the Royal Holloway University of London, and Alfie Lien, University of York as well as Sue Breakell and Jen Grasso at the Design Archives in the School of Humanities and Social Science. We also extend our thanks to Olivia Gecseg, Sarah Castagnetti, and Dave Lilley at the National Archives for all their support during the digitisation process.